 arXiv
arXiv
 Picture 1
Picture 1

This bowl of dessert sits on the gallery floor, reflecting the abstract art above.
1University of Science and Technology China 2Kling Team, Kuaishou Technology
Picture 1
This bowl of dessert sits on the gallery floor, reflecting the abstract art above.
 Picture 1
Picture 1
 Picture 2
Picture 2

I wish the person and the man would face each other in a cozy café.
 Picture 1
Picture 1

It sits in the cozy workspace on the wooden surface beside a steaming black coffee cup, its glossy skin catching the warm sunlight that filters through the window.
 Picture 1
Picture 1

The person in cosplay is sitting at a bustling restaurant table, smiling brightly as they pose for a picture with friends, their red eyes sparkling with excitement amidst the lively atmosphere.
 Picture 1
Picture 1

Dance on the stage beneath the red curtain.
 Picture 1
Picture 1
 Picture 2
Picture 2

He takes photos in the room.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3

Let the person from the second image stand thoughtfully beside the sculptural piece in the art gallery from the third image, while the plant from the first image rests on the floor nearby, adding a touch of greenery to the minimalist space.
 Picture 1
Picture 1

Show the person with curly hair standing by a marina, enjoying the view while holding a handbag.
 Picture 1
Picture 1
 Picture 2
Picture 2

Have the two people facing each other in a cozy café.
Picture 1
This bowl of dessert sits on the gallery floor, reflecting the abstract art above.
Picture 1
Picture 2
I wish the person and the man would face each other in a cozy café.
Picture 1
It sits in the cozy workspace on the wooden surface beside a steaming black coffee cup, its glossy skin catching the warm sunlight that filters through the window.
Picture 1
The person in cosplay is sitting at a bustling restaurant table, smiling brightly as they pose for a picture with friends, their red eyes sparkling with excitement amidst the lively atmosphere.
Picture 1
Dance on the stage beneath the red curtain.
Picture 1
Picture 2
He takes photos in the room.
Picture 1
Picture 2
Picture 3
Let the person from the second image stand thoughtfully beside the sculptural piece in the art gallery from the third image, while the plant from the first image rests on the floor nearby, adding a touch of greenery to the minimalist space.
Picture 1
Show the person with curly hair standing by a marina, enjoying the view while holding a handbag.
Picture 1
Picture 2
Have the two people facing each other in a cozy café.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3

I'd like the man from the first photo and the individual from img 2 to give a presentation in the religious site from the third image, surrounded by the row of golden Buddha statues in the serene and contemplative corridor.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3

Please have the individual in figure 1 hug the woman from picture 2 in the context in img 3, in the modern, stylish kitchen and dining area.
 Picture 1
Picture 1

The stylish person is on a television show set, joyfully hugging a friend while surrounded by bright studio lights and cameras.
 Picture 1
Picture 1
 Picture 2
Picture 2

Please make the person from the first figure and the man in the second photo eat together.
 Picture 1
Picture 1

She lies prone on the beach, staring straight at the camera while pursing her lips.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3
 Picture 4
Picture 4
 Picture 5
Picture 5

In a vibrant park, a woman in image 1 wears clothes in image 2, a vibrant floral skirt in various settings in image 3, a Supreme Logo Hat in image 4, and a Burberry Checkered Umbrella in image 5. She twirls happily among blooming flowers, the umbrella open to shield her from a light drizzle, while the hat shields her eyes from the soft sunlight peeking through clouds.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3
 Picture 4
Picture 4

A woman stands confidently in the opulent setting of a dimly lit space, adorned with a striking, shimmering dress in teal and black sequins, its loose fit and high neck adding a touch of elegance. Her outfit is completed with a sophisticated black satin turban featuring a sparkling brooch, adding a touch of glamour. The blurred background hints at an opulent environment with ambient glowing lights, lending an air of mystery and sophistication to the scene. Her posture suggests poise and grace, as she exudes a sense of being both part of the luxurious surroundings and the center of attention.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3

On a vanity bathed in soft light, a shimmering liquid highlighter for radiant glow from image 1 glistens next to a clear spirit in a glass bottle from image 2. Nearby, a gloss-enhancing serum for lustrous hair from image 3 adds an air of elegance, inviting beauty rituals in a serene morning setting.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3

A paddling watercraft, ideal for serene waters from image 1 floats gracefully on a tranquil lake, while a moisturizing, oil-infused bath bomb for skincare from image 2 rests on the sun-warmed shoreline. Nearby, a traditional formal outfit for men from image 3 is elegantly draped over a rock, creating an intriguing juxtaposition.
Picture 1
Picture 2
Picture 3
I'd like the man from the first photo and the individual from img 2 to give a presentation in the religious site from the third image, surrounded by the row of golden Buddha statues in the serene and contemplative corridor.
Picture 1
Picture 2
Picture 3
Please have the individual in figure 1 hug the woman from picture 2 in the context in img 3, in the modern, stylish kitchen and dining area.
Picture 1
The stylish person is on a television show set, joyfully hugging a friend while surrounded by bright studio lights and cameras.
Picture 1
Picture 2
Please make the person from the first figure and the man in the second photo eat together.
Picture 1
She lies prone on the beach, staring straight at the camera while pursing her lips.
Picture 1
Picture 2
Picture 3
Picture 4
Picture 5
In a vibrant park, a woman in image 1 wears clothes in image 2, a vibrant floral skirt in various settings in image 3, a Supreme Logo Hat in image 4, and a Burberry Checkered Umbrella in image 5. She twirls happily among blooming flowers, the umbrella open to shield her from a light drizzle, while the hat shields her eyes from the soft sunlight peeking through clouds.
Picture 1
Picture 2
Picture 3
Picture 4
A woman stands confidently in the opulent setting of a dimly lit space, adorned with a striking, shimmering dress in teal and black sequins, its loose fit and high neck adding a touch of elegance. Her outfit is completed with a sophisticated black satin turban featuring a sparkling brooch, adding a touch of glamour. The blurred background hints at an opulent environment with ambient glowing lights, lending an air of mystery and sophistication to the scene. Her posture suggests poise and grace, as she exudes a sense of being both part of the luxurious surroundings and the center of attention.
Picture 1
Picture 2
Picture 3
On a vanity bathed in soft light, a shimmering liquid highlighter for radiant glow from image 1 glistens next to a clear spirit in a glass bottle from image 2. Nearby, a gloss-enhancing serum for lustrous hair from image 3 adds an air of elegance, inviting beauty rituals in a serene morning setting.
Picture 1
Picture 2
Picture 3
A paddling watercraft, ideal for serene waters from image 1 floats gracefully on a tranquil lake, while a moisturizing, oil-infused bath bomb for skincare from image 2 rests on the sun-warmed shoreline. Nearby, a traditional formal outfit for men from image 3 is elegantly draped over a rock, creating an intriguing juxtaposition.
 Picture 1
Picture 1
 Picture 2
Picture 2

Inside a stylish living room, the women are dressed in polished business attire, one sitting on a chair and the other leaning on its backrest; they both look towards the camera with confident expressions, the angle slightly below eye level to convey authority and partnership.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3

On a sunny terrace, a woman in image 1 wears the clothes in image 2, enjoying a creamy blended ice cream beverage in image 3. She smiles as she watches the passing clouds, savoring the moment amidst the gentle breeze and vibrant flowers around her.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3

On a bustling city street, a woman in image 1 wears the black leather jacket in image 2, confidently straddling the racing moped in image 3, as the sun sets behind her, casting a golden glow on the scene, ready to speed into the horizon.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3
 Picture 4
Picture 4
 Picture 5
Picture 5

A man is standing on a serene beach, with the gentle waves lapping at the shore and fluffy clouds scattered across the bright blue sky. He wears a crisp white short-sleeve cotton shirt and light beige pants, both of which contrast elegantly with the natural hues of the sandy beach. Topping off his outfit is a stylish straw hat, shielding him from the sun. The man holds a coconut with a straw, embodying a vibe of tranquility and leisure in this picturesque coastal setting.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3
 Picture 4
Picture 4

In a vibrant garden, a woman in image 1 wears clothes in image 2, complemented by Khaki pants with multiple utility pockets in image 3. She gently exfoliates her skin with Soft gloves for gentle skin exfoliation in image 4, enjoying the sunlight as she tends to the blooming flowers around her.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3
 Picture 4
Picture 4

Underneath the tall and iconic Parisian landmark from image 1, a fast and maneuverable aquatic vehicle from image 2 glides gracefully along the Seine. Nearby, a compact travel caravan for outdoor adventures from image 3 is parked, while a bike with extended handlebars and low seat from image 4 leans against it, creating a vibrant setting of exploration and leisure by the riverbank.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3

In a quaint kitchen, an old woman in image 1 stands beside a tallboy dresser with multiple drawers in image 3, rummaging through it. On the table before her, a wide porcelain pasta bowl for serving in image 2 is filled with steaming pasta, ready for the family meal she's preparing.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3
 Picture 4
Picture 4

On a sunny afternoon in a vibrant garden, a man in image 1 sets up a weather-resistant outdoor rug for patios and gardens in image 3 under a large umbrella. Nearby, a woman in image 2 arranges cushions on the rug while discussing plans. A four-seater golf cart in image 4 stands ready at the edge of the garden, waiting to take them for a leisurely ride.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3

On a bustling city street, a man in image 1 wears a classic beige trench coat in image 2 and classic blue denim fashion staple in image 3. He strolls with confidence, the autumn breeze causing the trench coat to flutter slightly as he pauses to take in the vibrant urban life around him.
Picture 1
Picture 2
Inside a stylish living room, the women are dressed in polished business attire, one sitting on a chair and the other leaning on its backrest; they both look towards the camera with confident expressions, the angle slightly below eye level to convey authority and partnership.
Picture 1
Picture 2
Picture 3
On a sunny terrace, a woman in image 1 wears the clothes in image 2, enjoying a creamy blended ice cream beverage in image 3. She smiles as she watches the passing clouds, savoring the moment amidst the gentle breeze and vibrant flowers around her.
Picture 1
Picture 2
Picture 3
On a bustling city street, a woman in image 1 wears the black leather jacket in image 2, confidently straddling the racing moped in image 3, as the sun sets behind her, casting a golden glow on the scene, ready to speed into the horizon.
Picture 1
Picture 2
Picture 3
Picture 4
Picture 5
A man is standing on a serene beach, with the gentle waves lapping at the shore and fluffy clouds scattered across the bright blue sky. He wears a crisp white short-sleeve cotton shirt and light beige pants, both of which contrast elegantly with the natural hues of the sandy beach. Topping off his outfit is a stylish straw hat, shielding him from the sun. The man holds a coconut with a straw, embodying a vibe of tranquility and leisure in this picturesque coastal setting.
Picture 1
Picture 2
Picture 3
Picture 4
In a vibrant garden, a woman in image 1 wears clothes in image 2, complemented by Khaki pants with multiple utility pockets in image 3. She gently exfoliates her skin with Soft gloves for gentle skin exfoliation in image 4, enjoying the sunlight as she tends to the blooming flowers around her.
Picture 1
Picture 2
Picture 3
Picture 4
Underneath the tall and iconic Parisian landmark from image 1, a fast and maneuverable aquatic vehicle from image 2 glides gracefully along the Seine. Nearby, a compact travel caravan for outdoor adventures from image 3 is parked, while a bike with extended handlebars and low seat from image 4 leans against it, creating a vibrant setting of exploration and leisure by the riverbank.
Picture 1
Picture 2
Picture 3
In a quaint kitchen, an old woman in image 1 stands beside a tallboy dresser with multiple drawers in image 3, rummaging through it. On the table before her, a wide porcelain pasta bowl for serving in image 2 is filled with steaming pasta, ready for the family meal she's preparing.
Picture 1
Picture 2
Picture 3
Picture 4
On a sunny afternoon in a vibrant garden, a man in image 1 sets up a weather-resistant outdoor rug for patios and gardens in image 3 under a large umbrella. Nearby, a woman in image 2 arranges cushions on the rug while discussing plans. A four-seater golf cart in image 4 stands ready at the edge of the garden, waiting to take them for a leisurely ride.
Picture 1
Picture 2
Picture 3
On a bustling city street, a man in image 1 wears a classic beige trench coat in image 2 and classic blue denim fashion staple in image 3. He strolls with confidence, the autumn breeze causing the trench coat to flutter slightly as he pauses to take in the vibrant urban life around him.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3
 Picture 4
Picture 4
 Picture 5
Picture 5

A person with cascading blonde hair adorned with pastel highlights wears a ribbed brown tank top paired with light blue jeans featuring a brown belt, resting with an air of casual elegance. A beaded and layered necklace adds a bohemian flair, its colorful strands draped around the neck, complemented by a collection of bracelets on one wrist. In the background, the scene is set against a cozy interior accentuated with muted colors and simple decoration, including ceramic jugs, while a framed picture leans effortlessly on a shelf, adding a touch of artful intrigue to the setting.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3
 Picture 4
Picture 4
 Picture 5
Picture 5
 Picture 6
Picture 6
 Picture 7
Picture 7

Against the backdrop of a city street with blurred scooters parked alongside a stone building, a person stands confidently. Clad in a striking leopard-print coat with a classic collar, they balance edgy elegance with a pair of crisp white wide-legged jeans. Completing the outfit are sleek black ankle boots, adding a touch of sophistication. Draped casually around their shoulder is a striking black and beige striped handbag, while a grey scarf provides a subtle yet warming touch.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3
 Picture 4
Picture 4

A man sits confidently in front of a bustling café interior, his figure framing a scene with a menu board listing starters like cheese curds and taters, coffee makers, and a tray of golden fries resting on the counter. He is wearing a plain grey T-shirt from Image 1, complemented by a stylish grey cap emblazoned with an orange logo from Image 2.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3

In a sunlit garden, a woman in image 1 sits at a rustic table, cradling a hot beverage, served black or with milk. in image 2, while beside her, a hand tool for digging and planting. in image 3 leans against the table, ready for her afternoon gardening tasks.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3
 Picture 4
Picture 4

A woman with flowing brown hair from Image 3 is dressed in a delicate, white lace blouse similar to the one in Image 1. A vibrant red scarf from Image 2 adds a splash of color, visible in the water around her. Gentle waves from Image 4 lap onto the shore, creating a serene backdrop that complements her peaceful pose.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3
 Picture 4
Picture 4

A woman stands confidently in the foreground, dressed in a striking cheerleading outfit composed of a vibrantly detailed red, white, and navy blue top, paired with matching shorts that display sparkling embellishments. Her long, dark hair cascades over her shoulders. She poses with her arms raised, exuding energy amidst a bustling stadium atmosphere filled with excited fans, evident from the blurred figures and dynamic backdrop. The atmosphere is charged with anticipation, enhancing the high-energy scene.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3
 Picture 4
Picture 4
 Picture 5
Picture 5

Standing confidently in front of a rugged urban backdrop featuring a brick corner and partially visible bridge structure, a person with curly hair exudes a casual yet stylish vibe. Wearing a light denim jacket and tan work boots, their attire is completed by a flowing yellow and black checkered dress. The relaxed setting and outfit create a harmonious blend of city life and personal style.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3
 Picture 4
Picture 4

A person is wearing a vibrant green lace crop top with delicate floral patterns and thin straps. This top beautifully complements a pair of dark blue jeans, creating a stylish and modern ensemble. The subject stands against a soft gray background, adding a neutral canvas that enhances the vividness of the clothing. Their posture is relaxed, exuding confidence and style, making the outfit the focal point of the scene.
 Picture 1
Picture 1
 Picture 2
Picture 2
 Picture 3
Picture 3
 Picture 4
Picture 4
 Picture 5
Picture 5

A person is standing in a fitting room, posed with a relaxed posture against the backdrop of pale grey walls and mirrors that line the small cubicle. She is wearing a light purple blouse from Image 1, paired with distressed denim jeans from Image 2. Her footwear consists of beige espadrilles with playful cactus embroidery from Image 3. Her dark curly hair from Image 4 frames her face. The floor beneath her is a light wood tone, enhancing the cozy yet stylish atmosphere of the fitting room.
Picture 1
Picture 2
Picture 3
Picture 4
Picture 5
A person with cascading blonde hair adorned with pastel highlights wears a ribbed brown tank top paired with light blue jeans featuring a brown belt, resting with an air of casual elegance. A beaded and layered necklace adds a bohemian flair, its colorful strands draped around the neck, complemented by a collection of bracelets on one wrist. In the background, the scene is set against a cozy interior accentuated with muted colors and simple decoration, including ceramic jugs, while a framed picture leans effortlessly on a shelf, adding a touch of artful intrigue to the setting.
Picture 1
Picture 2
Picture 3
Picture 4
Picture 5
Picture 6
Picture 7
Against the backdrop of a city street with blurred scooters parked alongside a stone building, a person stands confidently. Clad in a striking leopard-print coat with a classic collar, they balance edgy elegance with a pair of crisp white wide-legged jeans. Completing the outfit are sleek black ankle boots, adding a touch of sophistication. Draped casually around their shoulder is a striking black and beige striped handbag, while a grey scarf provides a subtle yet warming touch.
Picture 1
Picture 2
Picture 3
Picture 4
A man sits confidently in front of a bustling café interior, his figure framing a scene with a menu board listing starters like cheese curds and taters, coffee makers, and a tray of golden fries resting on the counter. He is wearing a plain grey T-shirt from Image 1, complemented by a stylish grey cap emblazoned with an orange logo from Image 2.
Picture 1
Picture 2
Picture 3
In a sunlit garden, a woman in image 1 sits at a rustic table, cradling a hot beverage, served black or with milk. in image 2, while beside her, a hand tool for digging and planting. in image 3 leans against the table, ready for her afternoon gardening tasks.
Picture 1
Picture 2
Picture 3
Picture 4
A woman with flowing brown hair from Image 3 is dressed in a delicate, white lace blouse similar to the one in Image 1. A vibrant red scarf from Image 2 adds a splash of color, visible in the water around her. Gentle waves from Image 4 lap onto the shore, creating a serene backdrop that complements her peaceful pose.
Picture 1
Picture 2
Picture 3
Picture 4
A woman stands confidently in the foreground, dressed in a striking cheerleading outfit composed of a vibrantly detailed red, white, and navy blue top, paired with matching shorts that display sparkling embellishments. Her long, dark hair cascades over her shoulders. She poses with her arms raised, exuding energy amidst a bustling stadium atmosphere filled with excited fans, evident from the blurred figures and dynamic backdrop. The atmosphere is charged with anticipation, enhancing the high-energy scene.
Picture 1
Picture 2
Picture 3
Picture 4
Picture 5
Standing confidently in front of a rugged urban backdrop featuring a brick corner and partially visible bridge structure, a person with curly hair exudes a casual yet stylish vibe. Wearing a light denim jacket and tan work boots, their attire is completed by a flowing yellow and black checkered dress. The relaxed setting and outfit create a harmonious blend of city life and personal style.
Picture 1
Picture 2
Picture 3
Picture 4
A person is wearing a vibrant green lace crop top with delicate floral patterns and thin straps. This top beautifully complements a pair of dark blue jeans, creating a stylish and modern ensemble. The subject stands against a soft gray background, adding a neutral canvas that enhances the vividness of the clothing. Their posture is relaxed, exuding confidence and style, making the outfit the focal point of the scene.
Picture 1
Picture 2
Picture 3
Picture 4
Picture 5
A person is standing in a fitting room, posed with a relaxed posture against the backdrop of pale grey walls and mirrors that line the small cubicle. She is wearing a light purple blouse from Image 1, paired with distressed denim jeans from Image 2. Her footwear consists of beige espadrilles with playful cactus embroidery from Image 3. Her dark curly hair from Image 4 frames her face. The floor beneath her is a light wood tone, enhancing the cozy yet stylish atmosphere of the fitting room.
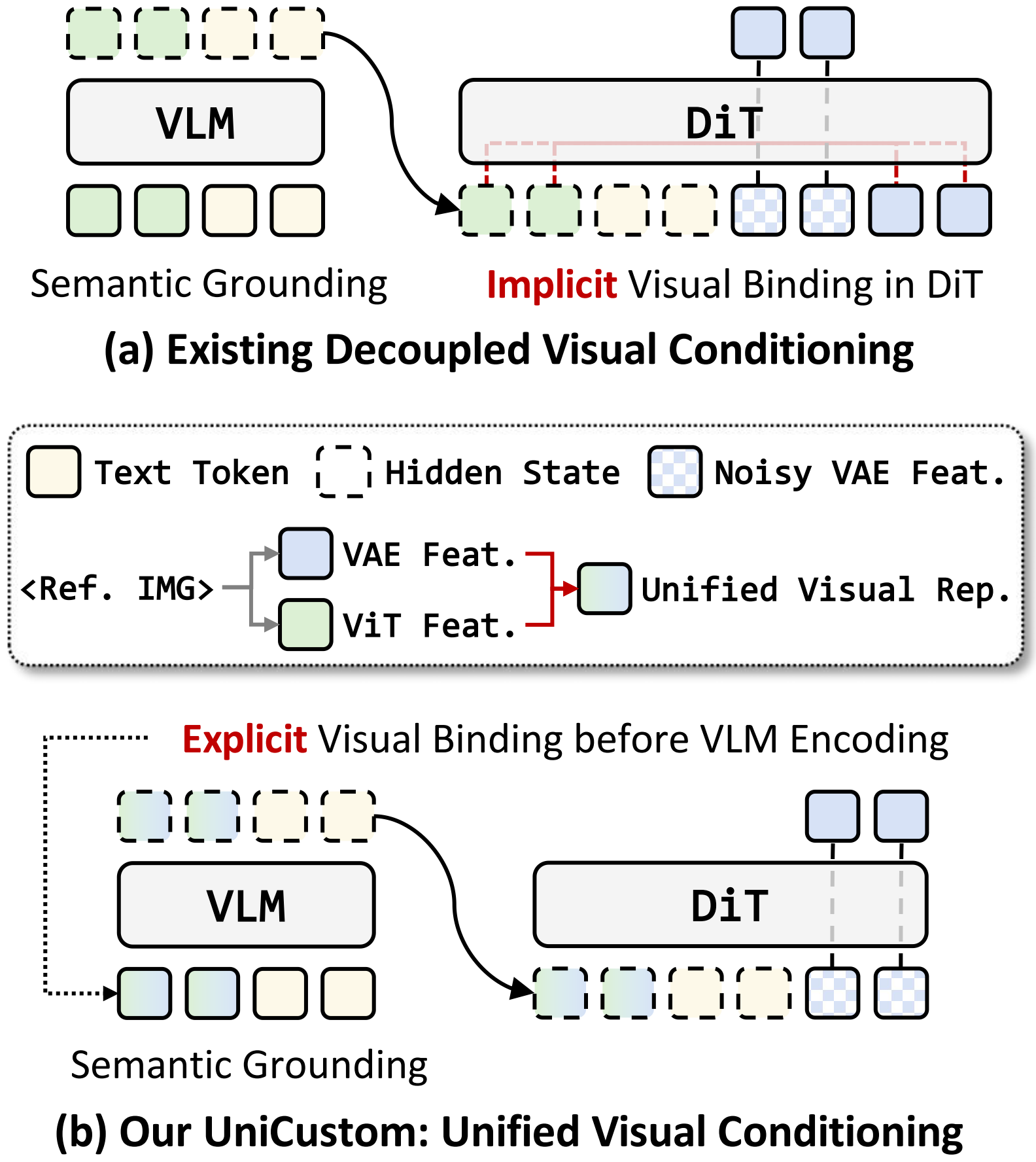
Multi-reference image generation aims to synthesize images from textual instructions while faithfully preserving subject identities from multiple reference images. Existing VLM-enhanced diffusion models commonly rely on decoupled visual conditioning: semantic ViT features are processed by the VLM for instruction understanding, whereas appearance-rich VAE features are injected later into the diffusion backbone. Despite its intuitive design, this separation makes it difficult for the model to associate each semantically grounded subject with visual details from the correct reference image, leading to attribute leakage and cross-reference confusion in complex multi-reference settings. To address this issue, we propose UniCustom, a unified visual conditioning framework that fuses ViT and VAE features before VLM encoding. This early fusion exposes the VLM to both semantic cues and appearance-rich details, enabling its hidden states to jointly encode the referred subject and corresponding visual appearance with only a lightweight linear fusion layer. We adopt a two-stage training strategy: reconstruction-oriented pretraining that preserves reference-specific appearance details in the fused hidden states, followed by supervised finetuning on single- and multi-reference generation tasks. We further introduce slot-wise binding regularization that encourages each image slot to preserve low-level details of its corresponding reference. Experiments on two multi-reference generation benchmarks demonstrate that UniCustom consistently improves subject consistency, instruction following, and compositional fidelity over strong baselines.
UniCustom introduces a lightweight early-fusion module that injects VAE features into ViT features before VLM encoding, enabling hidden states that are both semantically addressable and appearance-aware.
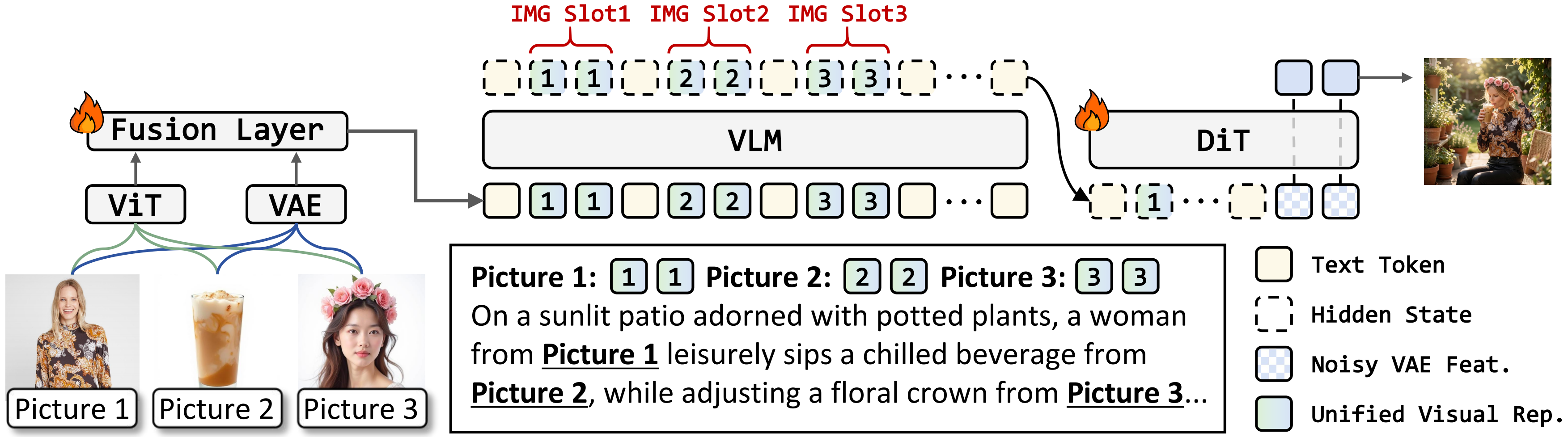
Overview of UniCustom. ViT and VAE features are fused before VLM encoding, producing semantically addressable and appearance-aware hidden states for DiT generation.
The VLM is kept frozen throughout both stages; only the lightweight fusion layer and the DiT are optimized, preserving pretrained multimodal understanding while progressively learning fine-grained visual binding.

Two-stage training strategy. The first stage progressively learns a unified visual representation that supports fine-grained reference encoding, semantic grounding, and reliable textual-to-visual binding through reconstruction-oriented multi-image pretraining. The second stage further adapts the diffusion backbone to reference-based image generation, enabling instruction-following synthesis with single or multiple reference images while preserving the learned grounding and binding abilities.
Fusion layer + DiT optimized. LR = 5×10-5, 18K steps.
Fusion layer frozen; only DiT optimized. LR = 1×10-5, 18K steps.
UniCustom achieves the best overall performance among open-source models on both OmniContext and MICo-Bench, with especially strong gains in multi-reference, scene-level, and compositional settings.
▸ OmniContext Benchmark
| Models | Single | Multiple | Scene | Average | |||||
|---|---|---|---|---|---|---|---|---|---|
| Character | Object | Character | Object | Char.+Obj. | Character | Object | Char.+Obj. | ||
| Closed-source Models | |||||||||
| GPT-Image-2 | 9.24 | 9.65 | 9.13 | 9.50 | 8.94 | 9.27 | 9.25 | 8.95 | 9.24 |
| Nano Banana 2 | 8.98 | 9.44 | 8.85 | 9.26 | 8.81 | 8.80 | 8.59 | 8.67 | 8.92 |
| Open-source Models | |||||||||
| FLUX-Kontext [dev] | 7.09 | 7.35 | 2.49 | 5.46 | 4.46 | 2.86 | 3.89 | 3.40 | 4.62 |
| UNO | 7.51 | 7.99 | 4.56 | 7.41 | 6.53 | 4.00 | 5.76 | 5.77 | 6.19 |
| USO | 7.71 | 7.68 | 2.91 | 7.27 | 5.61 | 3.88 | 6.49 | 6.04 | 5.95 |
| BAGEL | 7.12 | 7.70 | 5.86 | 7.07 | 6.79 | 4.98 | 6.05 | 6.03 | 6.45 |
| OmniGen2 | 8.04 | 7.87 | 7.22 | 7.76 | 7.51 | 7.52 | 7.30 | 7.57 | 7.60 |
| Qwen-Image-Edit-2509 | 8.11 | 9.01 | 7.85 | 8.53 | 7.60 | 5.88 | 7.38 | 7.12 | 7.69 |
| LongCat-Image-Edit | 8.24 | 8.63 | 6.69 | 8.07 | 6.99 | 5.80 | 6.73 | 6.98 | 7.26 |
| UniCustom (Ours) | 8.06 | 7.51 | 7.78 | 7.99 | 7.86 | 7.86 | 7.72 | 7.92 | 7.84 |
* "Char." and "Obj." denote "Character" and "Object", respectively.
▸ MICo-Bench
| Model | Object | Person | HOI | De&Re | Overall |
|---|---|---|---|---|---|
| Closed-source Models | |||||
| GPT-Image-2 | 66.93 | 60.56 | 59.02 | 62.69 | 61.78 |
| Nano Banana 2 | 68.46 | 65.88 | 64.88 | 70.28 | 67.42 |
| Open-source Models | |||||
| FLUX-Kontext [dev] | 21.40 | 14.33 | 12.67 | 7.24 | 12.51 |
| UNO | 42.20 | 15.15 | 27.99 | 41.93 | 32.43 |
| USO | 38.18 | 15.57 | 20.25 | 35.91 | 27.37 |
| BAGEL | 39.23 | 16.77 | 20.99 | 46.75 | 31.62 |
| Qwen-Image-Edit-2509 | 37.33 | 28.01 | 22.06 | 10.53 | 21.67 |
| LongCat-Image-Edit | 40.55 | 19.40 | 24.47 | 14.86 | 22.78 |
| UniCustom (Ours) | 54.30 | 18.12 | 40.51 | 50.29 | 41.71 |
* "HOI" and "De&Re" denote "Human-Object Interaction" and "Decomposition & Recomposition", respectively.
We identify the grounding--binding gap in VLM-enhanced diffusion models for multi-reference image generation. In existing decoupled conditioning designs, the DiT must implicitly associate VLM-encoded subject semantics with separately injected appearance features, which becomes unreliable with multiple references.
We propose UniCustom, a unified visual conditioning framework that makes reference appearances semantically accessible. By fusing ViT and VAE features before VLM encoding, UniCustom produces hidden states that jointly encode the referred subject and its fine-grained visual details, thereby providing the DiT with more explicit semantic--appearance correspondences.
We introduce a two-stage training strategy with slot-wise binding regularization to progressively learn reference-specific appearance preservation and adapt it to multi-reference generation. The reconstruction-oriented pretraining stage achieves a single-image reconstruction PSNR close to 30 dB, indicating that fused VLM hidden states can serve as an effective conduit for transmitting low-level details from VAE features to the DiT. Extensive experiments on two multi-reference image generation benchmarks further demonstrate that UniCustom outperforms existing methods.
If you find UniCustom useful in your research, please consider citing our paper.
@article{xu2026unicustom, title={UniCustom: Unified Visual Conditioning for Multi-Reference Image Generation}, author={Xu, Yiyan and Wang, Qiulin and Wang, Wenjie and Mao, Yunyao and Wang, Xintao and Wan, Pengfei and Gai, Kun and Feng, Fuli}, booktitle={arXiv preprint arXiv:2605.12088}, year={2026} }